The potential and pitfalls of machine learning in the Congruence Engine context
Article DOI: https://dx.doi.org/10.15180/221816
Abstract
This article considers the role of machine learning (ML) in the Congruence Engine project. The authors bring their digital and ML experience to the project and here reflect on existing tools and approaches, the particular challenges of Congruence Engine endeavour, and possible solutions within and beyond the project. Although these ideas will develop as the project progresses, the authors draw on knowledge of the existing ML landscape and current digital collections practice as well as learnings from Heritage Connector, the Science Museum Group’s previous project in the same funding scheme as Congruence Engine. The authors propose that while significant advances in ML and the availability of open datasets such as Wikidata offer huge opportunities for linking heritage collections, this will require a pipeline model with iterative stages of human intervention. Closer relationships will need to be developed between human curators, researchers and users of ML and the technology and processes it requires and this article points to the likely areas of collaboration that Congruence Engine will explore and test.
Keywords
Artificial Intelligence, digital humanities, Machine Learning, ML, Museum collections, natural language processing, Wikidata
Past practice in digital cultural heritage
Galleries, libraries, archives and museums (GLAMs) hold an enormous wealth of cultural heritage objects in their collections. Since the late 1990s, these institutions have been making moves to publish data and media relating to this content on the web through digitisation programmes. There are now well over 140 million individual items online from UK collections (Gosling, McKenna and Cooper, 2022). The resulting digital images and other media are accompanied online by their associated catalogue records. For the most part, these records are thin and many date back to a pre-digital era, having been transferred from paper records into internal collection management systems and from there to public websites (see Boon, this issue). These catalogue records and their associated images are for the most part published online at an individual institution level with a separate website for each institution and sometimes multiple collection websites for an institution.
However, these interfaces for discovery and exploration are limited by a number of factors. Firstly, there is a huge diversity of user needs: scholars and researchers, for example, require powerful advanced search features that enable fine-tuned discovery (which is frequently limited by the available data in the catalogue record), while general audiences tend to have more theme- and topic-based enquiries (Fildes, 2018) and are frequently searching for broader themes and topics than the catalogue supports. Secondly, as with all data, GLAM collection catalogues are reductive with the result that the form of the data may or may not align with the wide variety of user needs and their enquiries. Indeed, an instance of the same object occurring in multiple institutional collections – for example, a mass manufactured object such as a razor – will have a different catalogue record depending on the focus and interests of the individual GLAM institution: it could be a hand tool in one collection, part of a hygiene collection in another, and an adjunct to a fashion display in a third. Moreover, search features rely on the collection catalogue data whereas the content that users are seeking may be locked inside the collection item itself and therefore be undiscoverable: within features of images, within the text in the images, within oral history recordings, and so on. Indeed, the users’ points of interest may well be within related content such as details of people, companies, events or places, and not in the object per se. A third limiting factor for digital collections is that, although third-party search engines such as Google usually account for the overwhelming proportion of visits to online collections (approximately 70 per cent for the Science Museum Group Collection; source: Google Analytics), search engines generally poorly ‘understand’ GLAM collections online. The result is that they do not provide discovery beyond surfacing individual objects, and they usually struggle with search ranking objects from different institutions. Ranking is usually a measure of the search ranking and optimisation of the GLAM institution’s website rather than the relevance of individual objects to the user’s search terms. A fourth barrier is that collection objects exist in isolation within an institutional website, which is effectively a silo with each collection having few, if any, links to other websites. There is therefore little opportunity for users to move between collections to find related content or indeed to know what collections might include such related content.
Over recent years there have been various approaches to bringing collections together to enable users to discover, access and explore multiple collections as a single resource. These include large-scale aggregators such as ArtUK[1] and Europeana[2], which provide unified web interfaces through tight alignment of data to a unified model ahead of delivery through a single online user interface. Through this approach a high-quality user experience is delivered, but it is most suited to homogeneous object types, such as artworks. Barriers remain where objects are more varied, more complex, have thin records, and associated catalogue data is not consistent or comprehensive.
Any prospective researcher or user wanting to search collections effectively has to pass through a multi-stage process, repeated for each collection:
- knowing about the collection’s existence
- understanding that it may contain relevant content
- knowing that content is available online
- navigating the common pitfalls of text search: guessing search terms that will align with the terms in the collection catalogue
- having the desired content appear near the top of the results, potentially making multiple searches
- being able to see the relevance of the content to the search
- ideally, being able to navigate from that original content to related content.[3]
Throughout these stages, the form of GLAM collection catalogues and the nature of the websites on which they are published privileges some kinds of use over others. Unlocking greater potential for exploration, discovery and research by manually adding additional catalogue and other data to the digital record is possible but requires deep subject matter expertise that is extremely time consuming (and therefore expensive). Although this cataloguing is taking place across the cultural sector, it is progressing slowly even in large GLAM institutions that ostensibly have resources to deploy to this work.
Digital humanities and machine learning techniques
https://dx.doi.org/10.15180/221816/002Over the last decade, digital humanities (DH) methods and techniques have been increasingly applied to cultural heritage collections in part to address some of the challenges and limitations described above. DH projects usually create a pipeline combining computational methods and techniques alongside manual work. Rhiannon Lewis’s recent Landscape Study identified a number of DH methods and techniques that have been explored in recent projects and that are relevant to search and discovery within and across GLAM collections (Lewis, 2022). These are briefly explained here and their potential for Congruence Engine is selectively explored below. Categories discussed by Lewis, to whose document readers are referred for further detail, include:
- Application Programming Interfaces (API) to make existing structured data available for further computational use
- Linked Open Data (LOD) to make publicly accessible data that describes entities and the relationships between them, usually as ‘triples’ in the form subject-predicate-object, for example ‘Susan constructed a table’
- Network Analysis to understand and potentially visualise the relationships between objects in datasets, not just objects but also the people and places associated with them
- Knowledge Graphs (KG) to structure collections and other data in a graph format based on how the contained entities relate to each other, usually as Linked Open Data (see above)
- Data Visualisation to display catalogues and other data in ways that make large datasets coherent, answer specific questions, or enable exploration
- Crowdsourcing to generate additional data around collection objects (e.g., transcriptions, annotation, subject tags, etc.) usually using online interfaces, which can then be used for a variety of purposes
- Geographical Information System (GIS) to manage and display location data and allow exploration via places related to objects
- Persistent Identifiers (PIDs), the object equivalents of ORCIDs (the unique identifier system for academics[4]), to provide unique and unchanging references to resources including digitised objects.
As ML has improved in recent years, such techniques are now often combined with ML techniques, including:
- Computer Vision to extract content within digitised visual content (images, video and scans) to make this content searchable and enable further computer processing steps, for example identifying all images from the Science Museum Group collection which contain a loom
- Optical Character Recognition (OCR) to extract text from typed or typeset digitised documents so that the content can be used as data, including being searched or linked
- Handwritten Text Recognition (HTR) to extract text from handwritten digitised documents
- Natural Language Processing (NLP) to process text and audio to transform them into human and machine-readable data formats. Among the processes that NLP includes are sentiment analysis, speech recognition, translation, topic modelling, and named entity recognition (NER), disambiguation and entity linking (EL), which use algorithms trained to enable the identification within submitted texts of classes of terms such as names, dates, places or times.
These examples reveal the existence of a diverse range of DH and ML tools, all of which continue to evolve rapidly (see Calow, this issue). Some tools require specialist technical infrastructure and/or technical skills; others are usable by non-technical users, although it is likely that the higher the user’s technical skills, the more they will be able to get out of these tools. To train ML models to recognise new patterns and entity types, along with testing the performance of existing models, requires ‘training sets’ to be constructed and annotated by hand – often by users with an understanding of the materials – which can be a time-consuming process.
Uses of machine learning to connect digital collections
https://dx.doi.org/10.15180/221816/003Over recent years, advances in ML have significantly improved some of these methods and the approaches that can be undertaken more broadly in discovering, exploring and researching GLAM collections. In Heritage Connector, our previous smaller project under the Arts and Humanities Research Council’s (AHRC) Towards a National Collection (TaNC) funding programme, we formally experimented with some of these ML techniques.
The Heritage Connector project demonstrated that collection catalogue data and descriptions can be a rich source of potential links to other material (Winters et al, 2022). Here we processed the Science Museum Group catalogue data alongside a selection of similar data from the V&A, the published contents of this journal, the Science Museum blog and elements of Wikidata’s dataset into a single knowledge graph.
Catalogue descriptions, blog posts and articles, unlike the controlled fields in many collections catalogues (e.g., dates), exist as ‘free text’ prose. But we showed that it is possible to use natural language processing (NLP) to identify people, places, companies, etc., through named entity recognition (NER) within these various kinds of prose. It was then possible to link them together and to other datasets such as Wikidata through entity linking (EL). But it is important to clarify that NER alone only identifies ‘things that look like a person, place or company’ and in itself doesn’t identify specific people, places or companies. Therefore, a disambiguation stage was required after the NER to identify which specific person or place it might be. It is important to be able to distinguish, for example, between the father and son biologists JS and JBS Haldane, which can be done by reference to their respective dates of birth and death, for example. Because of the way they are trained, current – off-the-shelf pre-trained – machine-learning models do well at certain types of entity (people, laws, places, products, events, facilities, companies, organisations, etc., which are familiar terms for many industries) and less well at others, including object types, that are more bespoke to the cultural sector but less well documented and often not unique.

Heritage Connector provided proof of concept that heterogeneous collections data from different GLAMs can be combined in a free-standing knowledge graph; the work also undertook early and speculative demonstrations exploring the potential for creating useful interfaces into the graph.[5] In principle it is entirely possible to create a significantly larger graph containing data about many GLAM collections, but creating such an asset would require significant data wrangling and processing and a sharper focus on answering of new research questions to keep the approach and data manageable. Furthermore, it would not address the issue of keeping data live; the Heritage Connector approach involved a download at a particular moment in time, and so it could not readily be kept up to date with improvements and additions to source databases. Accordingly, Congruence Engine builds on the earlier project’s findings and will re-use some of its techniques, but the emphasis in the new project is in experimenting with a much wider variety of digital techniques to establish how digital linking can address the real-world research needs of curators and historians of every stripe.
New tools and techniques frequently emerge in ML. Their potential applications for GLAM collections and DH are therefore also rapidly transforming. As we saw in Heritage Connector, ML technologies do not return ‘perfect’ results; they often have no basis on which to distinguish differing usages of the same term. For example, ‘Victoria’ can be a person, a state in Australia, a station, an underground line in London or a song by The Fall. But ML techniques of the kinds we used in Heritage Connector do suggest the possibility of automating the cross-linking of collections records to other collections and to other online sources of contextualising data such as Wikidata; they thereby suggest new approaches and routes to research, exploration, discovery and public engagement.
ML can identify patterns. It can provide new insights into data (text, images, media files, etc.) but there needs to be a definable pattern that can be identified. Tasks therefore need to be pattern-oriented and ML models need to be trained to find these patterns. Training a machine-learning model usually involves providing large sets of examples that have been selected by human experts as representing the insights desired. Nevertheless, approaches using ML can be effective even when the patterns they recognise are ‘fuzzier’ (i.e. less narrowly categorised) than traditional human methods. For example, whereas traditional search interfaces may require multiple iterations using multiple query terms, ML can cluster related content based on proximity resulting in not only improved discovery but also surfacing closely related or adjacent content which the user may find valuable.
Once trained, ML models are, compared to humans, fast. So, ML can undertake tasks that would probably be rejected as too time consuming for humans. As with all software, ML is good at repetitive tasks. It can undertake a task, results can be reviewed, the approach or model tuned through human feedback and the process repeated seeking improved results. Humans are less good at speed and repetition, so subject matter experts are best deployed to review results if there is a desire to repeat and refine the task, minimising time and resource. ML is good at scale, as it can work across huge volumes of material, although as previously stated, the task must be pattern oriented. An analogy might be that although ML can ‘see the wood for the trees’, it needs to be trained to ‘know what the trees look like’. Traditionally the benefits of ML have been seen (in part correctly) as the ability to complete huge volumes of a task (or process vast datasets) much faster than humans can. But in reality, significant human work is needed to identify and train ML models to deliver the specific insights desired.
Machine learning and GLAM collections
https://dx.doi.org/10.15180/221816/004Given the significant potential of ML to improve exploration, discovery and research into GLAM collections, it is worth identifying key considerations for when and how to apply it. Firstly, once again, defining user needs is critical: we need to ask what value and insights are being sought and for whom? For example, what can’t people achieve within a given time period? What adds significant value, such as new links, or what might enable content to reveal unseen insights? Secondly, defining success criteria for the use of ML is important and, within this, what is ‘good enough’ to meet user needs is likely to vary; a large volume of data may contain many potential new insights, even though it may also contain irrelevant ‘false positives’; it is a matter of finding the right balance between recall and precision which addresses the task at hand. Thirdly, it is likely that to realise these success criteria, use of ML will require a pipeline approach with multiple stages including both manual data processing and review and ML steps. Depending on the desired outcomes, ML elements of such pipelines might include several digital techniques, as recorded by Lewis in her Landscape Study: crowdsourcing, OCR, data visualisation, GIS, HTR, knowledge graphs, LOD, NLP and network analysis. Human effort required in this pipeline might include selecting the most appropriate data content and fields, cleaning data, training and labelling data to train models, crowdsourcing, reviewing results, interpreting results and evaluating data clusters. Such work requires a ‘social machine’ approach alternating computation and human input. Moreover, non-technical staff will also need to be involved in ML projects at multiple stages in the pipeline. These stages might include analysis and selection of input data for pre-processing, training ML models by providing formatted examples, overseeing crowdsourcing projects to add additional data, reviewing outputs and data visualisations, and exploration or presentation of outputs.
Consideration needs to be given to input data. There might be multiple datasets and so careful selection requiring subject matter expertise will be needed. These datasets may include not only cultural heritage collection catalogues but also additional datasets, such as Wikidata, which can be used to deliver the desired outputs. Prior to use, data cleaning may well be required and this might be manual or computer assisted. Input data may also be needed for training ML models through labelling or example data. Some potential ML tasks could prove unviable due the level of manual labelling required to create a training dataset that can be used. Too much data might also be unhelpful as this is likely to skew outputs or result in overwhelmingly large outputs. Gaps in data can result in significant gaps in results, so pre-work is also needed to fully understand the available data.
Finally, building and maintaining custom ML software is difficult and resource intensive. So, in thinking about the ambition and needs for projects such as Congruence Engine it is worth exploring available software and the skills required to use them before embarking on building extensive new ML software. It is likely that any project will build on work underway by third parties – frequently for other sectors: legal, ecommerce, content discovery, etc. – and deploy those in the GLAM collections context.
Machine learning and Congruence Engine
https://dx.doi.org/10.15180/221816/005As we work through the first year of Congruence Engine, and as the project’s action research methodology surfaces the interests of the humanities researchers, the focus of the technical work is moving from the Heritage Connector concept of a combined multiple GLAM collection catalogue dataset to consideration of the points of interest and research aspects that can act as the connecting points between collections, or as entry points into multiple collections. It would be easy to assume that the collection catalogues do actually contain the content that is sought by users and that it simply needs unlocking at scale or across multiple collections. Because this is not (yet) the case, in Congruence Engine, we are confronted with the exciting possibility of addressing some of the limitations and challenges outlined above and exploring the potential of ML to address these.
It is generally the content of individual collections items – especially in publications and archives and other long-form or classified sources – that contains linking material, rather than the much sparser and less systematic catalogue data about the object, which is most often thought of when we conceive of ‘joining multiple museum collections’. For example, there is potential in working with oral histories to identify entities within them (people, places, companies, etc.) and link those to Wikidata and to other collections and sources. Or we might use the data about people and places in trade directories as potential joining points – ‘connective tissue’ – between catalogues of objects and other datasets using other entities: names, occupations, companies, addresses, for example.
Elements of Congruence Engine will draw on some of the same technologies as Heritage Connector. But the interests of participants in the current project point towards the use of a larger and much more diverse number of source collection catalogues than were used in that previous project. These are inevitably extremely variable in cataloguing format, approach and quality. Participant interests, for example in the social histories of mill workers, point to the need to extract content from within a variety of digitised objects (for example, structured tabular data in trade directories, terms used in oral history recordings, or industrial locations shown in films) to extract points of interest which can be used to cluster or range across larger volumes of source material. As described earlier, the approach to methods and techniques will require a pipeline approach with multiple steps, with machine learning used at various points.
It is valuable to examine in detail four areas of ML that are being considered for inclusion in the emerging Congruence Engine toolbox of methods and techniques.
Image recognition tools
Computer vision and image recognition tools are usually general purpose and off-the-shelf and therefore often poor in terms of expert classification, especially when applied far from their training data as in the case of GLAM collections. But they can be effective in terms of, for example, distinguishing the backs from the fronts of images, and for recognising types of document and general subject areas. Further training of such systems could allow tighter classification work such as identifying locomotive types (where such differences are identifiable from photographs). This is a case where these ML methods can allow sorting of large sets of images when key differences and characteristics are identifiable. It may be possible to leverage existing text, and terms within collection catalogues, to help train the system and thus classify images better. There are potentially ML advances that will allow the use of catalogue titles and text descriptions in combination with an image to extract additional extra information.
Optical Character Recognition (OCR)
Because OCR has improved dramatically in recent years due to ML, it shows real promise for Congruence Engine in relation to trade directories. This will especially be the case if the potential can be realised for layout parsing (which can liberate data from multiple and changing columnar layouts, for example). Resulting connective data would then be used in subsequent stages of a processing pipeline. For example, an analysis of all the residents of a town listed as ‘weavers’ could be linked to records for looms in museum collections of the same era.
Speech to text
Speech to text programs have also dramatically improved, meaning that for certain needs full manual transcriptions are not required for voice recordings, although colloquial and specialist words and phrases may prove complex to handle.
Fuzzy matching
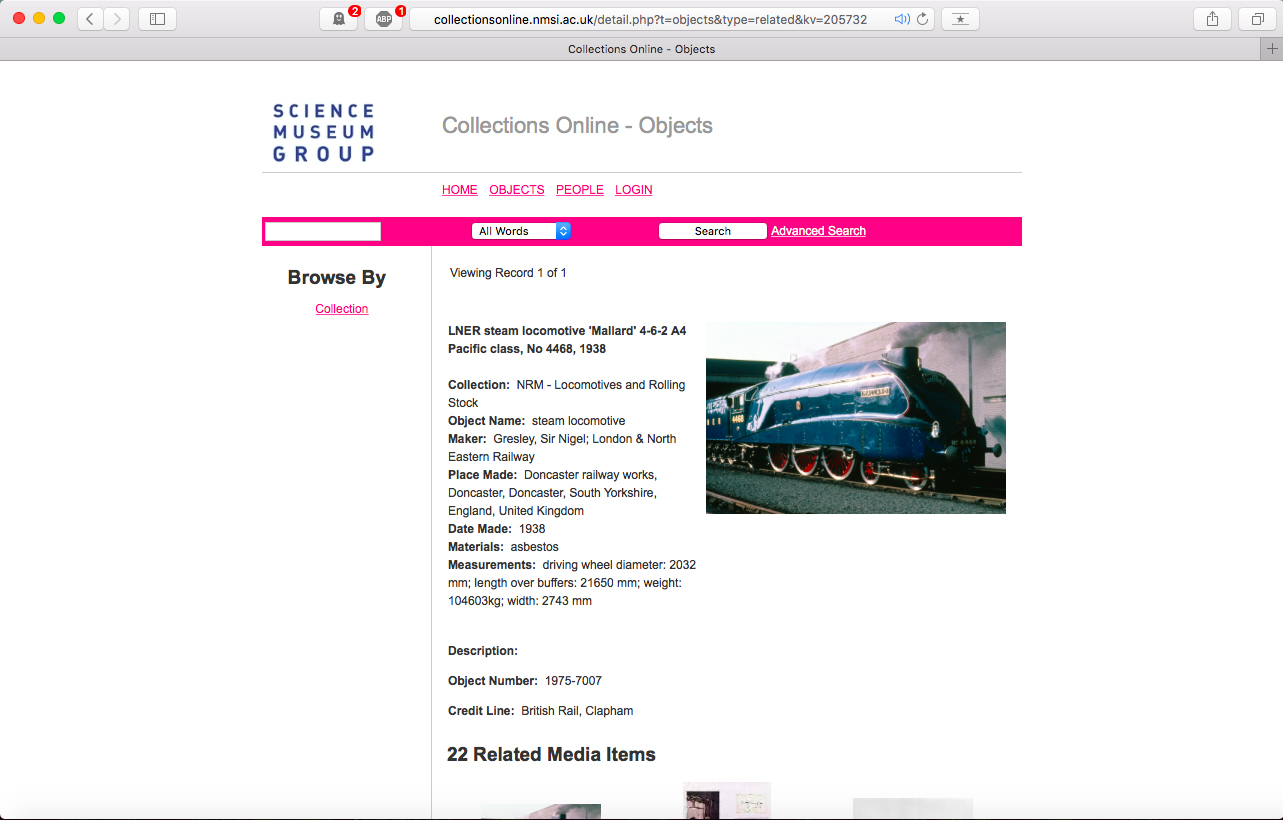
Instead of directly linking records for shared entities with formal relationships (for example, ‘here are locomotives designed by Nigel Gresley’, leading on to ‘this locomotive might also have been designed by him’), it might be possible to relate content together at a fuzzier – but still valuable – level. Here one can look at relationships and connections in terms of degrees of similarity, as for example is used in online bookselling sites: ‘If you like that book, you might like this one.’
These techniques to process the contents of oral histories, trade directories and other extensive ‘connective tissue’ sources may help us to identify lists of terms (‘entities’) which can then be used in downstream activities in the pipeline to process collection catalogue records and other datasets – possibly using methods such as fuzzy matching – to build a wider set of linked resources for researchers to use. These lists have the potential to structure the points of interest or connective tissue that draws together researchers’ needs. However, the approach raises several questions: What kind of data pre-processing might those lists need? What human effort is involved and what level of expertise? What kind of data repository would be needed to create and manage these lists? How scalable is this approach over multiple and potentially diverse data sources? These are the kinds of emerging questions that Congruence Engine is applying its efforts to.
Given the pipeline of methods needed for these approaches, it is critical to understand that different human skillsets are required at different stages. There will not be just a single approach to connecting types of data. Rather, different types of activity and skills are required at different stages: casual (non-expert) crowdsourcing may be adequate for identifying obvious errors or triaging data to be checked by an expert. Here volume/number of ‘down votes’ probably indicates a problem to be looked at, whereas one downvote might be a misunderstanding. Some degree of expert checking is likely to be required if using crowdsourcing, especially when outputs are to be used to train machine-learning models. For some kinds of checking, the expertise of a curator, specifically, will be needed.
Legacy beyond the Congruence Engine project
https://dx.doi.org/10.15180/221816/006It is important to consider the structuring and management of lists of connecting entities in ways that are usable with the pipeline, that are machine readable and that are available in the long term. To enable this high-level linkage, it is crucial to have a shared means of uniquely identifying the key points of intersection. Places, people, events and companies are obvious candidates, but as we move further into the specific nature of the individual themes of the Congruence Engine project (Textiles, Energy and Communication) we see that entities such as occupations, kinds of machinery and other object types, and industrial terminology are also important and common points of intersection.
While the Congruence Engine project could maintain its own lists of entities, taxonomies and ontologies (and most likely will in some areas), its aim is to act as a pilot for a more global endeavour of linking national collections. Therefore, for the more common (or notable) entities and verbs it makes sense to build upon existing linked datasets and public knowledge graphs such as Wikidata. Wikidata, a database of over 100 million unique items, is the sister project of Wikipedia and offers the potential to store and manage the data and to make it widely interoperable with wider datasets as linked open data (LOD). Using a public knowledge graph such as Wikidata also allows complex groupings and second-degree connections to be stored and retrieved in a single query – for example, a list of textile mills in Bradford between 1800 and 1900 or a list of machinery manufactured by a given company or for a particular purpose. Not only would the creation of new Wikidata entries (and the enhancement of existing entries) give us a central hub in which to store our common sets of entities and verbs, using existing tools and managed infrastructure, but it would also make them public for others to use or enhance. It would allow the work we do on Congruence Engine to connect to other projects and data, both now and in the future. Congruence Engine is well placed to extend the work already under way by the Wikidata community in showing and advocating how Wikidata could be used as this central hub, why it is the logical choice and what the practical steps and barriers are to using it.
One of the barriers to linking collections using LOD in general is the effort required and a focus on accuracy. Early project experiments (and the work on Heritage Connector) suggest that there is potential to look at creating these links at scale, but at a fuzzier level. For example, a researcher might think that a person is related to a particular object but there is little evidence of how or why (without spending human effort on researching, validating or improving connections). The solution here could be that ML finds fuzzy connections, followed by non-experts triaging, creating suggestions and marking suggestions, and then experts adjudicating on those that aren’t clear cut. One pitfall of this approach, especially if led by a cultural institution, could be reversion back to a single expert being required to check every edit. Accordingly, checks would be put into place to ensure that benefits can be realised without stalling at the expert human intervention stage, albeit that this would also need to account for the risk of imperfect data impacting on training of ML models downstream.
Conclusion
https://dx.doi.org/10.15180/221816/007Considering the role of ML in the Congruence Engine project, we are proposing that the forthcoming work may include using DH tools and ML methods to extract and structure as data the content of digitised GLAM collection objects. This data can then be used as the joining points between collections and other datasets. It is likely that a pipeline approach will be needed with several methods used and with human intervention required at multiple points in the process. ML is expected to significantly enhance the approaches taken. Wikidata may provide a useful tool for structuring and linking some of the datasets developed as part of the project and enabling them to be used by other projects and to have a legacy beyond the project’s lifetime. However, there remain challenges around training and use of ML models, handling complex content, and the need for human activity throughout the methods chosen. Some of these challenges may be overcome through use of cross-modal AI, retraining of models towards specific use cases such as those in Congruence Engine, exploring observability to better understand the machine-learning model’s behaviour, and focusing on data.
Tags
Footnotes
References
Authors


Media in article